C语言中堆与栈的含义解析
在编程领域中,c语言作为一种底层、高效的编程语言,广泛应用于系统软件开发、嵌入式系统等领域。理解和运用好c语言中的内存管理机制,对于编写高效、稳定的程序至关重要。堆(heap)和栈(stack)是c语言中两种基本的内存分配方式,它们各自有着独特的特性和用途。
栈(stack)是一种后进先出(lifo,last in first out)的数据结构,通常用于存储局部变量和函数调用信息。在c语言中,每当一个函数被调用时,该函数的局部变量、参数以及返回地址等信息会被压入栈中,形成一个栈帧(stack frame)。当函数执行完毕后,栈帧会被弹出,释放其占用的内存空间。栈的管理是由编译器自动完成的,程序员通常不需要显式地进行内存分配和释放操作。由于栈的内存分配和释放效率非常高,且栈空间通常是连续的,因此栈非常适合用于存储需要频繁访问、生命周期较短的数据。
与栈不同,堆(heap)是一种用于动态内存分配的区域。在c语言中,堆的内存分配和释放需要程序员显式地进行,通常通过`malloc`、`calloc`、`realloc`和`free`等函数来实现。堆内存的使用更加灵活,可以根据需要在程序运行时动态地分配和释放内存。然而,由于堆内存的管理需要程序员自行控制,因此也更容易出现内存泄漏、野指针等问题。在使用堆内存时,程序员需要特别小心,确保在适当的时候释放已分配的内存,以避免内存泄漏。
在实际编程中,选择使用栈还是堆主要取决于数据的生命周期和访问模式。对于生命周期较短、访问频繁的数据,如局部变量和函数调用信息,通常使用栈来存储。而对于生命周期较长、大小不固定的数据,如动态数组、链表等数据结构,则更适合使用堆来存储。
此外,值得注意的是,虽然栈和堆在内存管理中扮演着不同的角色,但它们并不是完全独立的。在某些情况下,栈和堆之间会进行交互,如函数返回指针指向堆中分配的内存等。因此,在编写c语言程序时,程序员需要深入理解栈和堆的特性和用法,以确保程序的正确性和稳定性。
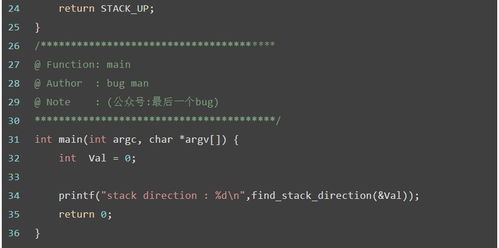
综上所述,c语言中的堆和栈是两种基本的内存分配方式,它们各自有着独特的特性和用途。栈适用于存储生命周期短、访问频繁的数据,而堆则适用于存储生命周期长、大小不固定的数据。在实际编程中,程序员需要根据数据的生命周期和访问模式来选择使用栈还是堆,并谨慎管理内存,以避免潜在的内存问题。